
티스토리 뷰

AI Rush 대비 + PyTorch로 이사 대비용
In [1]:
import os
import shutil
original_dataset_dir = './dataset'
classes_list = os.listdir(original_dataset_dir)
base_dir = './splitted'
os.makedirs(base_dir, exist_ok=True)
train_dir = os.path.join(base_dir, 'train')
validation_dir = os.path.join(base_dir, 'val')
test_dir = os.path.join(base_dir, 'test')
os.makedirs(train_dir, exist_ok=True)
os.makedirs(validation_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
for clss in classes_list:
os.makedirs(os.path.join(train_dir, clss), exist_ok=True)
os.makedirs(os.path.join(validation_dir, clss), exist_ok=True)
os.makedirs(os.path.join(test_dir, clss), exist_ok=True)
In [2]:
import math
for clss in classes_list:
path = os.path.join(original_dataset_dir, clss)
fnames = os.listdir(path)
train_size = math.floor(len(fnames) * 0.6)
validation_size = math.floor(len(fnames) * 0.2)
test_size = math.floor(len(fnames) * 0.2)
train_fnames = fnames[:train_size]
print('Train size(', clss, '):', len(train_fnames))
for fname in train_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(train_dir, clss), fname)
shutil.copyfile(src, dst)
validation_fnames = fnames[train_size:(train_size + validation_size)]
print('validation size(', clss, '):', len(validation_fnames))
for fname in validation_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(validation_dir, clss), fname)
shutil.copyfile(src, dst)
test_fnames = fnames[(train_size +
validation_size):(train_size + validation_size +
test_size)]
print('Test size(', clss, '):', len(test_fnames))
for fname in test_fnames:
src = os.path.join(path, fname)
dst = os.path.join(os.path.join(test_dir, clss), fname)
shutil.copyfile(src, dst)
Train size( Apple___Apple_scab ): 378
validation size( Apple___Apple_scab ): 126
Test size( Apple___Apple_scab ): 126
Train size( Apple___Black_rot ): 372
validation size( Apple___Black_rot ): 124
Test size( Apple___Black_rot ): 124
Train size( Apple___Cedar_apple_rust ): 165
validation size( Apple___Cedar_apple_rust ): 55
Test size( Apple___Cedar_apple_rust ): 55
Train size( Apple___healthy ): 987
validation size( Apple___healthy ): 329
Test size( Apple___healthy ): 329
Train size( Cherry___healthy ): 512
validation size( Cherry___healthy ): 170
Test size( Cherry___healthy ): 170
Train size( Cherry___Powdery_mildew ): 631
validation size( Cherry___Powdery_mildew ): 210
Test size( Cherry___Powdery_mildew ): 210
Train size( Corn___Cercospora_leaf_spot Gray_leaf_spot ): 307
validation size( Corn___Cercospora_leaf_spot Gray_leaf_spot ): 102
Test size( Corn___Cercospora_leaf_spot Gray_leaf_spot ): 102
Train size( Corn___Common_rust ): 715
validation size( Corn___Common_rust ): 238
Test size( Corn___Common_rust ): 238
Train size( Corn___healthy ): 697
validation size( Corn___healthy ): 232
Test size( Corn___healthy ): 232
Train size( Corn___Northern_Leaf_Blight ): 591
validation size( Corn___Northern_Leaf_Blight ): 197
Test size( Corn___Northern_Leaf_Blight ): 197
Train size( Grape___Black_rot ): 708
validation size( Grape___Black_rot ): 236
Test size( Grape___Black_rot ): 236
Train size( Grape___Esca_(Black_Measles) ): 829
validation size( Grape___Esca_(Black_Measles) ): 276
Test size( Grape___Esca_(Black_Measles) ): 276
Train size( Grape___healthy ): 253
validation size( Grape___healthy ): 84
Test size( Grape___healthy ): 84
Train size( Grape___Leaf_blight_(Isariopsis_Leaf_Spot) ): 645
validation size( Grape___Leaf_blight_(Isariopsis_Leaf_Spot) ): 215
Test size( Grape___Leaf_blight_(Isariopsis_Leaf_Spot) ): 215
Train size( Peach___Bacterial_spot ): 1378
validation size( Peach___Bacterial_spot ): 459
Test size( Peach___Bacterial_spot ): 459
Train size( Peach___healthy ): 216
validation size( Peach___healthy ): 72
Test size( Peach___healthy ): 72
Train size( Pepper,_bell___Bacterial_spot ): 598
validation size( Pepper,_bell___Bacterial_spot ): 199
Test size( Pepper,_bell___Bacterial_spot ): 199
Train size( Pepper,_bell___healthy ): 886
validation size( Pepper,_bell___healthy ): 295
Test size( Pepper,_bell___healthy ): 295
Train size( Potato___Early_blight ): 600
validation size( Potato___Early_blight ): 200
Test size( Potato___Early_blight ): 200
Train size( Potato___healthy ): 91
validation size( Potato___healthy ): 30
Test size( Potato___healthy ): 30
Train size( Potato___Late_blight ): 600
validation size( Potato___Late_blight ): 200
Test size( Potato___Late_blight ): 200
Train size( Strawberry___healthy ): 273
validation size( Strawberry___healthy ): 91
Test size( Strawberry___healthy ): 91
Train size( Strawberry___Leaf_scorch ): 665
validation size( Strawberry___Leaf_scorch ): 221
Test size( Strawberry___Leaf_scorch ): 221
Train size( Tomato___Bacterial_spot ): 1276
validation size( Tomato___Bacterial_spot ): 425
Test size( Tomato___Bacterial_spot ): 425
Train size( Tomato___Early_blight ): 600
validation size( Tomato___Early_blight ): 200
Test size( Tomato___Early_blight ): 200
Train size( Tomato___healthy ): 954
validation size( Tomato___healthy ): 318
Test size( Tomato___healthy ): 318
Train size( Tomato___Late_blight ): 1145
validation size( Tomato___Late_blight ): 381
Test size( Tomato___Late_blight ): 381
Train size( Tomato___Leaf_Mold ): 571
validation size( Tomato___Leaf_Mold ): 190
Test size( Tomato___Leaf_Mold ): 190
Train size( Tomato___Septoria_leaf_spot ): 1062
validation size( Tomato___Septoria_leaf_spot ): 354
Test size( Tomato___Septoria_leaf_spot ): 354
Train size( Tomato___Spider_mites Two-spotted_spider_mite ): 1005
validation size( Tomato___Spider_mites Two-spotted_spider_mite ): 335
Test size( Tomato___Spider_mites Two-spotted_spider_mite ): 335
Train size( Tomato___Target_Spot ): 842
validation size( Tomato___Target_Spot ): 280
Test size( Tomato___Target_Spot ): 280
Train size( Tomato___Tomato_mosaic_virus ): 223
validation size( Tomato___Tomato_mosaic_virus ): 74
Test size( Tomato___Tomato_mosaic_virus ): 74
Train size( Tomato___Tomato_Yellow_Leaf_Curl_Virus ): 3214
validation size( Tomato___Tomato_Yellow_Leaf_Curl_Virus ): 1071
Test size( Tomato___Tomato_Yellow_Leaf_Curl_Virus ): 1071
베이스라인 모델¶
전이 학습 없이 기본적인 CNN 구조로 된 모델이다.
나중에 전이 학습된 모델과 비교해보기.
In [3]:
import torch
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device('cuda' if USE_CUDA else 'cpu')
BATCH_SIZE = 256
EPOCH = 30
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
# transform을 진행할 요소들을 한번에 진행한다.
transform_base = transforms.Compose(
[transforms.Resize((64, 64)),
transforms.ToTensor()])
train_dataset = ImageFolder(root='./splitted/train', transform=transform_base)
val_dataset = ImageFolder(root='./splitted/val', transform=transform_base)
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
val_loader = DataLoader(val_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
In [4]:
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 64, 3, padding=1)
self.fc1 = nn.Linear(4096, 512)
self.fc2 = nn.Linear(512, 33)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = self.conv3(x)
x = F.relu(x)
x = self.pool(x)
x = F.dropout(x, p=0.25, training=self.training)
x = x.view(-1, 4096)
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x, p=0.5, training=self.training)
x = self.fc2(x)
return F.log_softmax(x, dim=1)
model_base = Net().to(DEVICE)
optimizer = optim.Adam(model_base.parameters(), lr=0.001)
In [5]:
def train(model, train_loader, optim):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
ouput = model(data)
loss = F.cross_entropy(ouput, target)
loss.backward()
optimizer.step()
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad(): # Parameter 업데이트가 중단된다.
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target,
reduction='sum').item()
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_acc = 100. * correct / len(test_loader.dataset)
return test_loss, test_acc
In [6]:
import time
import copy
def train_baseline(model, train_loader, val_loader, optimizer, num_epochs=30):
best_acc = 0.0
best_model_wts = copy.deepcopy(model.state_dict())
for epoch in range(1, num_epochs + 1):
since = time.time()
train(model, train_loader, optimizer)
train_loss, train_acc = evaluate(model, train_loader)
val_loss, val_acc = evaluate(model, val_loader)
if val_acc > best_acc:
best_acc = val_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('--------------epoch {}----------------'.format(epoch))
print('train Loss: {:.4f}, Acc: {:.2f}%'.format(train_loss, train_acc))
print('test Loss: {:.4f}, Acc: {:.2f}%'.format(val_loss, val_acc))
print('Completed in {:.0f}m {:.0f}s'.format(time_elapsed // 60,
time_elapsed % 60))
model.load_state_dict(best_model_wts)
return model
In [7]:
base = train_baseline(model_base, train_loader, val_loader, EPOCH)
torch.save(base, 'baseline.pt')
--------------epoch 1----------------
train Loss: 2.0753, Acc: 41.08%
test Loss: 2.0890, Acc: 40.87%
Completed in 0m 32s
--------------epoch 2----------------
train Loss: 1.2743, Acc: 63.10%
test Loss: 1.3081, Acc: 62.12%
Completed in 0m 28s
--------------epoch 3----------------
train Loss: 0.9434, Acc: 70.75%
test Loss: 0.9932, Acc: 69.30%
Completed in 0m 29s
--------------epoch 4----------------
train Loss: 0.8013, Acc: 75.21%
test Loss: 0.8608, Acc: 73.60%
Completed in 0m 30s
--------------epoch 5----------------
train Loss: 0.6308, Acc: 80.57%
test Loss: 0.6942, Acc: 78.12%
Completed in 0m 29s
--------------epoch 6----------------
train Loss: 0.5958, Acc: 81.27%
test Loss: 0.6700, Acc: 78.66%
Completed in 0m 29s
--------------epoch 7----------------
train Loss: 0.5524, Acc: 82.40%
test Loss: 0.6282, Acc: 79.77%
Completed in 0m 29s
--------------epoch 8----------------
train Loss: 0.4328, Acc: 87.06%
test Loss: 0.5056, Acc: 84.17%
Completed in 0m 29s
--------------epoch 9----------------
train Loss: 0.3977, Acc: 87.56%
test Loss: 0.4760, Acc: 85.15%
Completed in 0m 29s
--------------epoch 10----------------
train Loss: 0.3607, Acc: 88.32%
test Loss: 0.4489, Acc: 85.04%
Completed in 0m 29s
--------------epoch 11----------------
train Loss: 0.3323, Acc: 89.66%
test Loss: 0.4180, Acc: 86.69%
Completed in 0m 29s
--------------epoch 12----------------
train Loss: 0.2797, Acc: 91.63%
test Loss: 0.3748, Acc: 88.31%
Completed in 0m 30s
--------------epoch 13----------------
train Loss: 0.2790, Acc: 91.79%
test Loss: 0.3742, Acc: 88.21%
Completed in 0m 29s
--------------epoch 14----------------
train Loss: 0.2283, Acc: 93.33%
test Loss: 0.3259, Acc: 89.62%
Completed in 0m 30s
--------------epoch 15----------------
train Loss: 0.2330, Acc: 93.10%
test Loss: 0.3468, Acc: 88.82%
Completed in 0m 30s
--------------epoch 16----------------
train Loss: 0.2161, Acc: 93.37%
test Loss: 0.3296, Acc: 89.34%
Completed in 0m 30s
--------------epoch 17----------------
train Loss: 0.2607, Acc: 91.83%
test Loss: 0.3838, Acc: 87.24%
Completed in 0m 29s
--------------epoch 18----------------
train Loss: 0.1838, Acc: 94.47%
test Loss: 0.3036, Acc: 89.99%
Completed in 0m 29s
--------------epoch 19----------------
train Loss: 0.1731, Acc: 95.29%
test Loss: 0.2881, Acc: 90.69%
Completed in 0m 29s
--------------epoch 20----------------
train Loss: 0.1644, Acc: 94.91%
test Loss: 0.2879, Acc: 90.75%
Completed in 0m 29s
--------------epoch 21----------------
train Loss: 0.1592, Acc: 95.34%
test Loss: 0.2878, Acc: 90.59%
Completed in 0m 29s
--------------epoch 22----------------
train Loss: 0.1420, Acc: 96.26%
test Loss: 0.2637, Acc: 91.86%
Completed in 0m 29s
--------------epoch 23----------------
train Loss: 0.1361, Acc: 96.24%
test Loss: 0.2694, Acc: 91.03%
Completed in 0m 28s
--------------epoch 24----------------
train Loss: 0.1278, Acc: 96.32%
test Loss: 0.2581, Acc: 91.68%
Completed in 0m 27s
--------------epoch 25----------------
train Loss: 0.1166, Acc: 96.92%
test Loss: 0.2535, Acc: 91.94%
Completed in 0m 27s
--------------epoch 26----------------
train Loss: 0.1149, Acc: 96.89%
test Loss: 0.2492, Acc: 91.88%
Completed in 0m 27s
--------------epoch 27----------------
train Loss: 0.1153, Acc: 96.47%
test Loss: 0.2615, Acc: 91.50%
Completed in 0m 27s
--------------epoch 28----------------
train Loss: 0.1000, Acc: 97.35%
test Loss: 0.2415, Acc: 92.26%
Completed in 0m 27s
--------------epoch 29----------------
train Loss: 0.0928, Acc: 97.76%
test Loss: 0.2266, Acc: 92.66%
Completed in 0m 28s
--------------epoch 30----------------
train Loss: 0.1010, Acc: 97.15%
test Loss: 0.2461, Acc: 91.98%
Completed in 0m 29s
Transfer Learning¶
미리 학습된(re trainied) 모델을 이용하여 다른 주제의 분류 작업에 이용할 수 있다.
이런 모델들은 대용량의 데이터셋으로 학습되어 성능이 좋기에 이 모델들을 조정하면(Fine-Tuning)
다른 작업이더라도 좋은 성과를 얻을 수 있다.
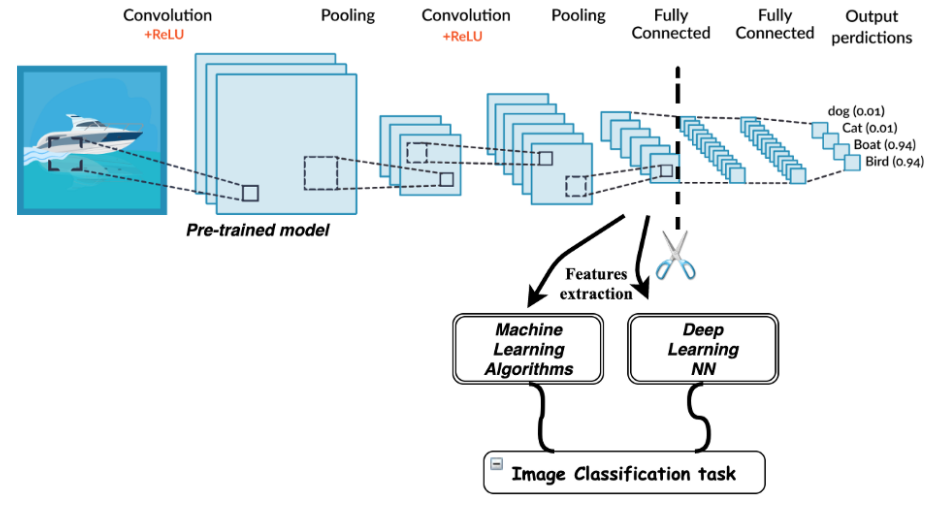
보통 하위층의 특성맵에서 작은 지역 패턴들이, 상위층에서는 고수준의 특징들을 가지고 있기에 모델을 조정할 때는
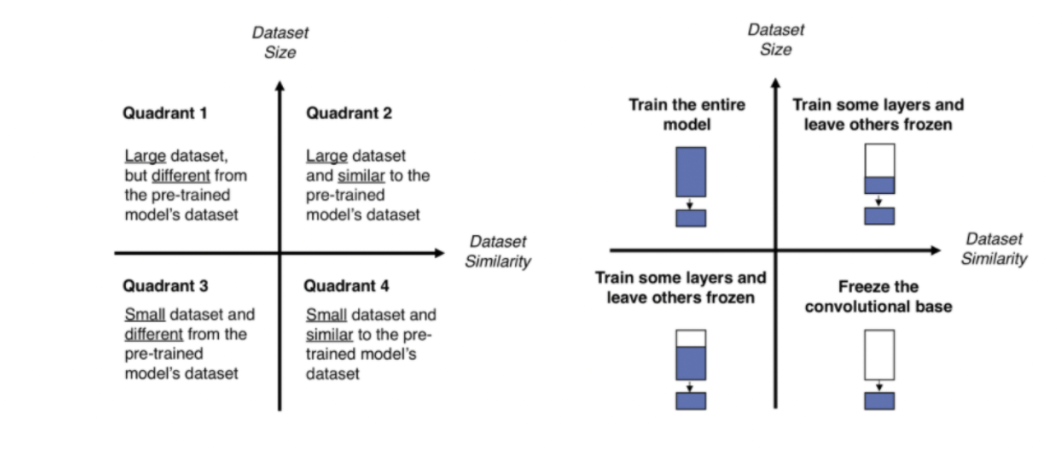
분류기와 가까운 layer부터 적절하게 업데이트시켜준다. (이외 layer들은 동결처리)
보통 현재 문제에 대한 데이터셋의 크기와 사전훈련 과정에서 이용된 데이터셋과의 유사성을 기준으로 정한다.
In [8]:
data_transforms = {
'train':
transforms.Compose([
transforms.Resize([64, 64]),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'val':
transforms.Compose([
transforms.Resize([64, 64]),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
}
data_dir = './splitted'
image_datasets = {
x: ImageFolder(root=os.path.join(data_dir, x),
transform=data_transforms[x])
for x in ['train', 'val']
}
dataloaders = {
x: torch.utils.data.DataLoader(image_datasets[x],
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
for x in ['train', 'val']
}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'val']}
class_names = image_datasets['train'].classes
In [9]:
from torchvision import models
resnet = models.resnet50(pretrained=True)
num_ftrs = resnet.fc.in_features
# 마지막 출력 채널의 출력값을 변경해주자. (33개의 클래스로)
resnet.fc = nn.Linear(num_ftrs, 33)
resnet = resnet.to(DEVICE)
criterion = nn.CrossEntropyLoss()
# filter 함수가 2번째 iterable한 자료형을 받아서 람다 함수로 넘겨준다.
# 이때 requires_grad = True 인 파라미터만 넘어가게 된다.
optimizer_ft = optim.Adam(filter(lambda p: p.requires_grad,
resnet.parameters()),
lr=0.001)
from torch.optim import lr_scheduler
# 7 Epoch 마다 학습률에 0.1을 곱해줌
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
C:\Users\hesh0\anaconda3\lib\site-packages\torchvision\models\_utils.py:208: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
warnings.warn(
C:\Users\hesh0\anaconda3\lib\site-packages\torchvision\models\_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=ResNet50_Weights.IMAGENET1K_V1`. You can also use `weights=ResNet50_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
모델 준비는 마쳤으니 일부 Layer를 Freeze 해주자
In [10]:
ct = 0
for child in resnet.children(): # resnet.children() == 모든 Layer 정보가 담겨있다
ct += 1
if ct < 6:
for param in child.parameters():
param.requires_grad = False
In [11]:
for idx,child in enumerate(resnet.children()): # resnet.children() == 모든 Layer 정보가 담겨있다.
print('---------cur is {}--------'.format(idx))
print(child,'\n')
---------cur is 0--------
Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
---------cur is 1--------
BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
---------cur is 2--------
ReLU(inplace=True)
---------cur is 3--------
MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
---------cur is 4--------
Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
---------cur is 5--------
Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
---------cur is 6--------
Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
---------cur is 7--------
Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
---------cur is 8--------
AdaptiveAvgPool2d(output_size=(1, 1))
---------cur is 9--------
Linear(in_features=2048, out_features=33, bias=True)
In [12]:
def train_resnet(model, criterion, optimizer, scheduler, num_epochs=25):
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('----------------epoch {}--------------'.format(epoch + 1))
since = time.time()
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0
for inputs, labels in dataloaders[phase]:
inputs = inputs.to(DEVICE)
labels = labels.to(DEVICE)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
l_r = [x['lr'] for x in optimizer_ft.param_groups]
print('learning rate: ', l_r)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss,
epoch_acc))
if phase == 'val' and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Completed in {:.0f}m {:.0f}s'.format(time_elapsed // 60,
time_elapsed % 60))
print('Best val Acc: {:.4f}'.format(best_acc))
model.load_state_dict(best_model_wts)
return model
In [13]:
model_resnet50 = train_resnet(resnet,
criterion,
optimizer_ft,
exp_lr_scheduler,
num_epochs=EPOCH)
torch.save(model_resnet50, 'resnet50.pt')
----------------epoch 1--------------
learning rate: [0.001]
train Loss: 0.5923 Acc: 0.8235
val Loss: 0.2868 Acc: 0.9081
Completed in 0m 24s
----------------epoch 2--------------
learning rate: [0.001]
train Loss: 0.2342 Acc: 0.9222
val Loss: 0.2201 Acc: 0.9254
Completed in 0m 23s
----------------epoch 3--------------
learning rate: [0.001]
train Loss: 0.1654 Acc: 0.9481
val Loss: 0.2391 Acc: 0.9273
Completed in 0m 23s
----------------epoch 4--------------
learning rate: [0.001]
train Loss: 0.1347 Acc: 0.9559
val Loss: 0.1379 Acc: 0.9554
Completed in 0m 23s
----------------epoch 5--------------
learning rate: [0.001]
train Loss: 0.1231 Acc: 0.9600
val Loss: 0.1164 Acc: 0.9632
Completed in 0m 23s
----------------epoch 6--------------
learning rate: [0.001]
train Loss: 0.0927 Acc: 0.9703
val Loss: 0.0944 Acc: 0.9711
Completed in 0m 23s
----------------epoch 7--------------
learning rate: [0.0001]
train Loss: 0.0778 Acc: 0.9748
val Loss: 0.1293 Acc: 0.9566
Completed in 0m 23s
----------------epoch 8--------------
learning rate: [0.0001]
train Loss: 0.0439 Acc: 0.9850
val Loss: 0.0446 Acc: 0.9867
Completed in 0m 23s
----------------epoch 9--------------
learning rate: [0.0001]
train Loss: 0.0270 Acc: 0.9917
val Loss: 0.0392 Acc: 0.9871
Completed in 0m 23s
----------------epoch 10--------------
learning rate: [0.0001]
train Loss: 0.0228 Acc: 0.9921
val Loss: 0.0352 Acc: 0.9876
Completed in 0m 23s
----------------epoch 11--------------
learning rate: [0.0001]
train Loss: 0.0212 Acc: 0.9930
val Loss: 0.0320 Acc: 0.9886
Completed in 0m 23s
----------------epoch 12--------------
learning rate: [0.0001]
train Loss: 0.0181 Acc: 0.9937
val Loss: 0.0342 Acc: 0.9885
Completed in 0m 23s
----------------epoch 13--------------
learning rate: [0.0001]
train Loss: 0.0174 Acc: 0.9944
val Loss: 0.0329 Acc: 0.9890
Completed in 0m 23s
----------------epoch 14--------------
learning rate: [1e-05]
train Loss: 0.0158 Acc: 0.9943
val Loss: 0.0319 Acc: 0.9905
Completed in 0m 23s
----------------epoch 15--------------
learning rate: [1e-05]
train Loss: 0.0159 Acc: 0.9947
val Loss: 0.0316 Acc: 0.9909
Completed in 0m 23s
----------------epoch 16--------------
learning rate: [1e-05]
train Loss: 0.0134 Acc: 0.9958
val Loss: 0.0303 Acc: 0.9901
Completed in 0m 23s
----------------epoch 17--------------
learning rate: [1e-05]
train Loss: 0.0135 Acc: 0.9956
val Loss: 0.0305 Acc: 0.9907
Completed in 0m 23s
----------------epoch 18--------------
learning rate: [1e-05]
train Loss: 0.0130 Acc: 0.9959
val Loss: 0.0291 Acc: 0.9909
Completed in 0m 23s
----------------epoch 19--------------
learning rate: [1e-05]
train Loss: 0.0126 Acc: 0.9960
val Loss: 0.0278 Acc: 0.9916
Completed in 0m 23s
----------------epoch 20--------------
learning rate: [1e-05]
train Loss: 0.0115 Acc: 0.9964
val Loss: 0.0310 Acc: 0.9902
Completed in 0m 23s
----------------epoch 21--------------
learning rate: [1.0000000000000002e-06]
train Loss: 0.0121 Acc: 0.9959
val Loss: 0.0261 Acc: 0.9914
Completed in 0m 23s
----------------epoch 22--------------
learning rate: [1.0000000000000002e-06]
train Loss: 0.0119 Acc: 0.9964
val Loss: 0.0297 Acc: 0.9904
Completed in 0m 23s
----------------epoch 23--------------
learning rate: [1.0000000000000002e-06]
train Loss: 0.0113 Acc: 0.9965
val Loss: 0.0324 Acc: 0.9900
Completed in 0m 23s
----------------epoch 24--------------
learning rate: [1.0000000000000002e-06]
train Loss: 0.0126 Acc: 0.9962
val Loss: 0.0247 Acc: 0.9925
Completed in 0m 23s
----------------epoch 25--------------
learning rate: [1.0000000000000002e-06]
train Loss: 0.0112 Acc: 0.9968
val Loss: 0.0287 Acc: 0.9911
Completed in 0m 23s
----------------epoch 26--------------
learning rate: [1.0000000000000002e-06]
train Loss: 0.0118 Acc: 0.9965
val Loss: 0.0309 Acc: 0.9896
Completed in 0m 23s
----------------epoch 27--------------
learning rate: [1.0000000000000002e-06]
train Loss: 0.0117 Acc: 0.9961
val Loss: 0.0310 Acc: 0.9897
Completed in 0m 22s
----------------epoch 28--------------
learning rate: [1.0000000000000002e-07]
train Loss: 0.0121 Acc: 0.9958
val Loss: 0.0260 Acc: 0.9927
Completed in 0m 24s
----------------epoch 29--------------
learning rate: [1.0000000000000002e-07]
train Loss: 0.0119 Acc: 0.9963
val Loss: 0.0287 Acc: 0.9912
Completed in 0m 24s
----------------epoch 30--------------
learning rate: [1.0000000000000002e-07]
train Loss: 0.0110 Acc: 0.9960
val Loss: 0.0282 Acc: 0.9910
Completed in 0m 24s
Best val Acc: 0.9927
모델 평가¶
기존 CNN으로 만든 Baseline 모델과 Transfer learning을 통해 학습한 모델을 비교해보자.
In [20]:
transform_base = transforms.Compose(
[transforms.Resize([64, 64]),
transforms.ToTensor()])
test_base = ImageFolder(root='./splitted/test', transform=transform_base)
test_loader_base = torch.utils.data.DataLoader(test_base,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
transform_resNet = transforms.Compose([
transforms.Resize([64, 64]),
transforms.RandomCrop(52),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
test_resNet = ImageFolder(root='./splitted/test', transform=transform_resNet)
test_loader_resNet = torch.utils.data.DataLoader(test_resNet,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4)
In [21]:
baseline = torch.load('baseline.pt')
baseline.eval()
test_loss, test_accuracy = evaluate(baseline, test_loader_base)
print('baseline test acc:\t', test_accuracy)
baseline test acc: 92.42708724496183
In [22]:
resnet50 = torch.load('resnet50.pt')
resnet50.eval()
test_loss, test_accuracy = evaluate(resnet50, test_loader_resNet)
print('ResNet test acc:\t', test_accuracy)
ResNet test acc: 99.17386406308674
'AI' 카테고리의 다른 글
| [Docker] 기본 명령어 정리 (0) | 2022.07.09 |
|---|---|
| [핸즈온 머신러닝] chapter 15. RNN (0) | 2022.06.01 |
| [핸즈온 머신러닝] chapter 14. 합성곱 신경망 (0) | 2022.05.18 |
| [핸즈온 머신러닝] chapter 13. 텐서플로에서의 데이터 적재와 전처리 (0) | 2022.05.04 |
| [핸즈온 머신러닝] chapter 12. 텐서플로에서의 사용자 정의 모델과 훈련 (0) | 2022.04.28 |
댓글
공지사항
최근에 올라온 글
최근에 달린 댓글
- Total
- Today
- Yesterday