
티스토리 뷰
Convolutional Neural Network
논문 자체는 1989년에 나왔지만 여전히 컴퓨터 비전 분야에서 유용하게 쓰이는 인공 신경망인 CNN.
사람이 물체를 인식하는 방식에서 아이디어를 얻었는데 우리는 시야에 들어온 이미지 전체를 인식하지 않는다.
당연하게도 물체만에 집중하기 때문이다. 하지만 또 물체를 전부 통째로 인식할까? 아니다.
물체에도 부분적인 특성이 존재하고 그 특성들을 잘 살펴보면 가로, 세로, 대각선, 색상으로 구성된다.
우리는 이런 특성들이 주변 지역과 어떻게 이어지는지를 기억하고 나중에 비슷한 물체를 보면 떠올린다!
어떻게 생각하면 전반적인 특성을 쓰윽 보고 서서히 지역적인 특성을 본 다음
추상적인 개념을 떠올린다고 생각할 수 있다. 이런 특성을 신경망에서도 학습할 수 있다면?
정말 좋겠지만 그동안 쓰이던 Dense layer에는 문제가 있었다.

합성곱 신경망이 나오게 된 배경
지금까지 본 Dense 하게 연결된 계층을 이용하게 되면 인접하는 계층의 뉴런과 모두 연결되고
출력되는 데이터의 수 또한 임의로 정할 수 있다는 장점이 있었다.
하지만 과연 이것이 이미지 인식에도 도움이 될까?
이미지는 일반적으로 가로, 세로, 채널(색상)로 구성된 3차원 데이터이다.
따라서 이 구조에는 공간적인 정보가 담겨있다. 예를 들어 특정 픽셀들끼리 같은 색상을 가지거나 선이 이어지는 등...
그런데 이 데이터를 Dense층에 넣어버리면 이 모든 데이터들이 연결되고 섞여서 정보를 잃게 된다.
그렇기에 이런 지역적인 특성을 저장하면서도 효율적으로 다음 계층으로 넘겨줄 방법이 필요했는데 그것이 CNN이다.
합성곱 계층의 연산
우선 CNN에서의 Conv layer의 입출력 데이터를 특징 맵 (figure map)이라고 한다.
입력 데이터는 input feature map, 출력 데이터는 output feature map이라고 한다.
Conv layer는 이렇게 들어온 input feature map에 대하여 필터를 이용하여 연산을 진행하게 된다.
다음과 같이 입력 특성 맵에 필터를 적용하면 각각의 위치에 상응하는 입력 맵의 값과 필터 값을 곱하여 더해준다.
그리고 또한 Dense 계층에 편향(bias) 값이 존재했던 것처럼 Conv layer에도 bias값이 존재하므로 더해주면 끝!
이렇게 되면 4*4 입력 맵이 3*3 필터가 적용되면서 2*2 출력 맵으로 변화하는 것을 알 수 있다.
만일 이렇게 출력 맵의 사이즈가 줄어드는 것이 싫다면? 입력 데이터 가장자리에 0으로 채워주면 될 것이다.
이를 패딩(padding)이라고 부르고 출력 맵의 사이즈를 조정하는데 이용할 수 있다.
예를 들어 4*4 입력 맵에 폭 1짜리 패딩을 적용해서 6*6 사이즈로 만들어주면 3*3 필터를 적용해도 4*4로 뽑혀 나온다.
이처럼 패딩을 이용하여 출력 크기를 조정해주면 필터를 계속해서 적용하다가 크기가 작아지면서
결국 크기가 1이 돼버리는 상황을 막아줄 수 있다.
필터를 적용하는 위치가 위의 예시에서는 1칸씩 옮겨갔지만 여러 칸씩 옮겨줄 수 있다.
이를 스트라이드 (stride)라고 부른다.
이렇게 입력 데이터에 패딩과 스트라이드를 적용하면 출력 크기가 어떻게 될까?
입력 크기를 (H, W), 필터 크기를 (FH, FW), 출력 크기를 (OH, OW), 패딩을 P, 스트라이드를 S라 할 때
출력 크기는 다음 식을 따른다.
그런데 저 식이 딱 안 나누어 떨어지고 나머지가 생긴다면 프레임워크에 따라서 반올림되거나 다른 결과를 낼 수 있다.
더 나아가 이미지 데이터는 가로 세로뿐만 아니라 채널(색상)이라는 값이 존재하는 3차원 데이터이다.
따라서 입력 데이터의 채널 수만큼의 필터의 채널 역시 같은 개수만큼 존재한다.
계산 방식은 여전히 같지만 하나의 입력 데이터에 하나의 필터가 대응되어 더해진다.
결과를 보아하니 출력 맵이 하나의 채널을 가진 특징 맵으로 나오는 것을 알 수 있다.
만약 다수의 채널을 다음 레이어에 전달하려면 다수의 필터를 이용하면 된다.
(위의 있는 사진이 다수의 필터처럼 보이지만 저 자체가 하나의 필터이다. 하나의 필터가 여러 채널을 들고 있는 셈)
이러면 필터의 개수만큼 출력 맵 또한 필터의 개수만큼의 채널을 가지게 된다.
이와 비슷한 논리로 배치 처리를 진행한다면 Dense 계층에서 차원을 하나 더 늘려서 배치 개수만큼 넣어줬던 것처럼
Conv 계층 또한 차원을 하나 더 늘려서 배치 개수만큼 넣어주면 신경망에 배치 개수만큼의 데이터가 한꺼번에 흐른다.
풀링(Pooling) 계층
풀링 계층은 가로 세로 방향의 공간을 줄여준다. 기껏 정보를 받아왔는데 왜 줄이냐고 할 수 있겠다만 이유가 있다.
1. 만약 이미지가 살짝 왼쪽으로 움직였다고 생각해보자. 그러면 당연하게도 Conv 레이어에서 계산되는 값이 달라진다.
하지만 풀링 계층을 이용해서 인근 지역의 최댓값만 뽑아준다면? 이미지가 이동해도 나오는 값은 동일해진다.
이처럼 이미지 특성이 이동하는 경우 이를 살리기 위하여 사용된다.
2. 데이터 차원을 줄여준다. 따라서 메모리를 덜 먹으니 효율성이 올라간다.
보통은 2*2 최대 풀링 (max pooling)을 이용하여 2*2 영역에 있는 값들 중 최댓값만 뽑아다가 반환해준다.
이외에도 평균 풀링 (avg pooling)이라고 해서 영역에 있는 모든 값들을 평균 내다가 반환해준다.
물론 이미지 인식에서는 최대 풀링을 주로 이용한다고 한다.
(그래서 그런지 여러 논문에서도 풀링이라고 하면 맥스 풀링을 의미했다.)
워나 연산이 단순하다 보니 일단 학습할 가중치 파라미터가 존재하지 않는다.
게다가 입력 데이터의 모든 채널에 적용되니 출력 데이터 또한 채널 수가 유지된다.
그리고 위에서도 설명했지만 입력값이 조금 변하더라도 결괏값이 크게 안 변한다.
CNN 출력 맵을 시각화 해보자!
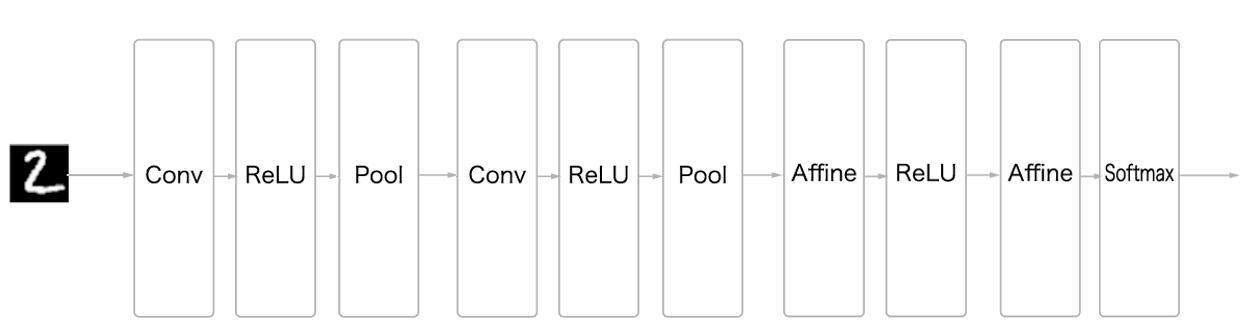
보통 여러겹의 Conv-ReLU-Pooling(종종 생략) 레이어들을 묶어서 여러번 이용하고 마지막에 Softmax를 이용하여
레이블마다의 확률들을 뽑아다가 가장 높은 확률을 가진 값을 예상 정답으로 둔다.
(ILSVRC에서는 상위 5개 레이블들중에 하나라도 정답이면 정답 처리해주기도 했었다)
그런데 맨 위에서 CNN은 인간이 물체를 인식하는 방식대로 인식한다고 했는데 지금까지 만든 모델에는 그런 부분이
시각적으로는 안보인다. 그렇다면 각각의 학습된 필터들이 무엇을 학습하고 보는지 알아보자.
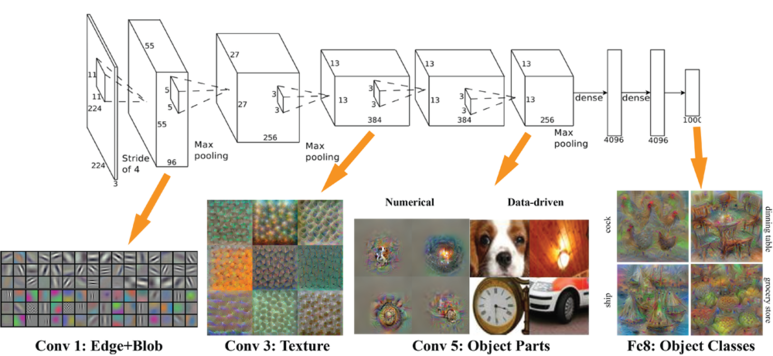
ILSVRC 2012에서 우승한 AlexNet의 구조와 필터를 시각화한 결과이다.
초기에는 대략적인 특성에 반응하지만 점점 질감과 같은 높은 수준의 정보에 반응하더니
더 들어갈수록 사물의 일부, 또는 추상적인 개념에까지 접근한다는 것을 알 수있다.
이는 우리가 사물을 인지하는 방식과 굉장히 유사하다.
CNN이 세상에 나오고 높은 정확도를 보이자 어떻게 활용할지가 주된 관심사가 되었고 다양한 타입의 CNN이 등장한다.
너무 글이 길어지니 다음시간에 GoogLe Net과 VGG 신경망을 써봐야겠다.
- Total
- Today
- Yesterday